Chapter 8 Reproducible research
Learning Objectives
- Understand the concept of reproducible research and reproducible documents.
- Understand the process by which a source document is compiled into a final report.
- Generate a reproducible report in html or pdf from an Rmarkdown document using RStudio.
For a general introduction on the topic in French, see Pouzat, Davison, and Hinsen (2015Pouzat, Christophe, Andrew Davison, and Konrad Hinsen. 2015. “La Recherche Reproductible : Une Communication Scientifique Explicite.” Statistique Et Société 3 (1). http://www.publications-sfds.fr/index.php/stat_soc/article/view/448.). If you want to explore the topic of reproducible research in French, the Recherche reproductible : principes méthodologiques pour une science transparente MOOC is of interest.
Reproducible research refers to research that can be reproduced under various conditions and by different people. It applies to every area of research, both experimental and computational, but is often (but not always) easier to implement for computational work. The different levels of reproducibility can formalised13 The nomenclature is taken from this blog post that provides links and highlights that confusion that exists around the terms and concepts of reproducibility. as follows:
Repeat my experiment, i.e. obtain the same tables/graphs/results using the same setup (data, software, …) in the same lab or on the same computer. That’s basically re-running one of my analysis some time after I original developed it.
Reproduce an experiment (not ones own), i.e. obtain the same tables/graphs/results in a different lab or on a different computer, using the same setup (the data would be downloaded from a public repository and the same software, but possibly using a different version, or a different operation system).
Replicate an experiment, i.e. obtain the same (similar enough) tables/graphs/results in a different set up. The data could still be downloaded from the public repository, or possibly re-generated/re-simulated, and the analysis would be re-implemented based on the original description.
Finally, re-use the information/knowledge from one experiment to run a different experiment with the aim to confirm results from scratch.
The table below summerised these concepts focusing on data and code in computational projects.
| Same data | Different data | |
|---|---|---|
| Same code | Repeat | Reproduce |
| Different code | Reproduce | Replicate |
There are many reasons to work reproducibly, and Markowetz (2015Markowetz, Florian. 2015. “Five Selfish Reasons to Work Reproducibly.” Genome Biology 16 (1): 274. https://doi.org/10.1186/s13059-015-0850-7.) nicely summarises 5 good reasons. Importantly, he stressed out that the first beneficiary of reproducible work are the student/researcher that apply these principles:
- Reproducibility helps to avoid disaster.
- Reproducibility makes it easier to write papers14 And course reports! The exam of this course will consist in a reproducible report using the tools described below..
- Reproducibility helps reviewers see it your way15 Not only reviewers, also professors that read exams. See previous footnote..
- Reproducibility enables continuity of your work.
- Reproducibility helps to build your reputation.
8.1 knitr and rmarkdown
Reproducible research is an essential part of any data analysis. With the tools that are available, one can argue that it has become more difficult not to produce reproducible reports than to producing then.
Reproducible documents have been a part of R since the very
beginning. See for example R. Gentleman and Temple Lang (2004Gentleman, Robert, and Duncan Temple Lang. 2004. “Statistical Analyses and Reproducible Research.” Bioconductor Project Working Papers. Working Paper 2. https://biostats.bepress.com/bioconductor/paper2.), to see how such compendia play a
central role within the Bioconductor
project (more about Bioconductor in it’s dedicated
chapter). Originally, these were written in LaTeX, interleaved with R
code chunks, forming so called Sweave documents (with extension
.Rnw).
 Figure 8.1: The rmarkdown sticker
Figure 8.1: The rmarkdown sticker
More recently, it has become to use the
markdown syntax
markup language, rather than LaTeX. Once interleaved with R code
chunks, these documents become Rmarkdown files (.Rmd). The can be
converted into markdown using knitr::knit, that executes the code
chunk and incorporates their output in the resulting markdown
documents, which itself is converted to one of many output formats,
typically pdf of html using pandoc. In R, this
final conversion is done using rmarkdown::render (that relies on
pandoc).
knitr::knitconverts theRmdintomdby executing the code chunks and replacing the code by its output (text, tables, figures, …).The
mdfile is then compiled into the desired output format (typically html or pdf) usingpandoc.In practice, in R, these two steps are automatically handled in one go by
rmarkdown::render().
Figure 8.2: The rmarkdown workflow (image from RStudio)

The rmarkdown package is developed and maintained by RStudio and benefits from excellent documentation, support and integrates into the RStudio editor.
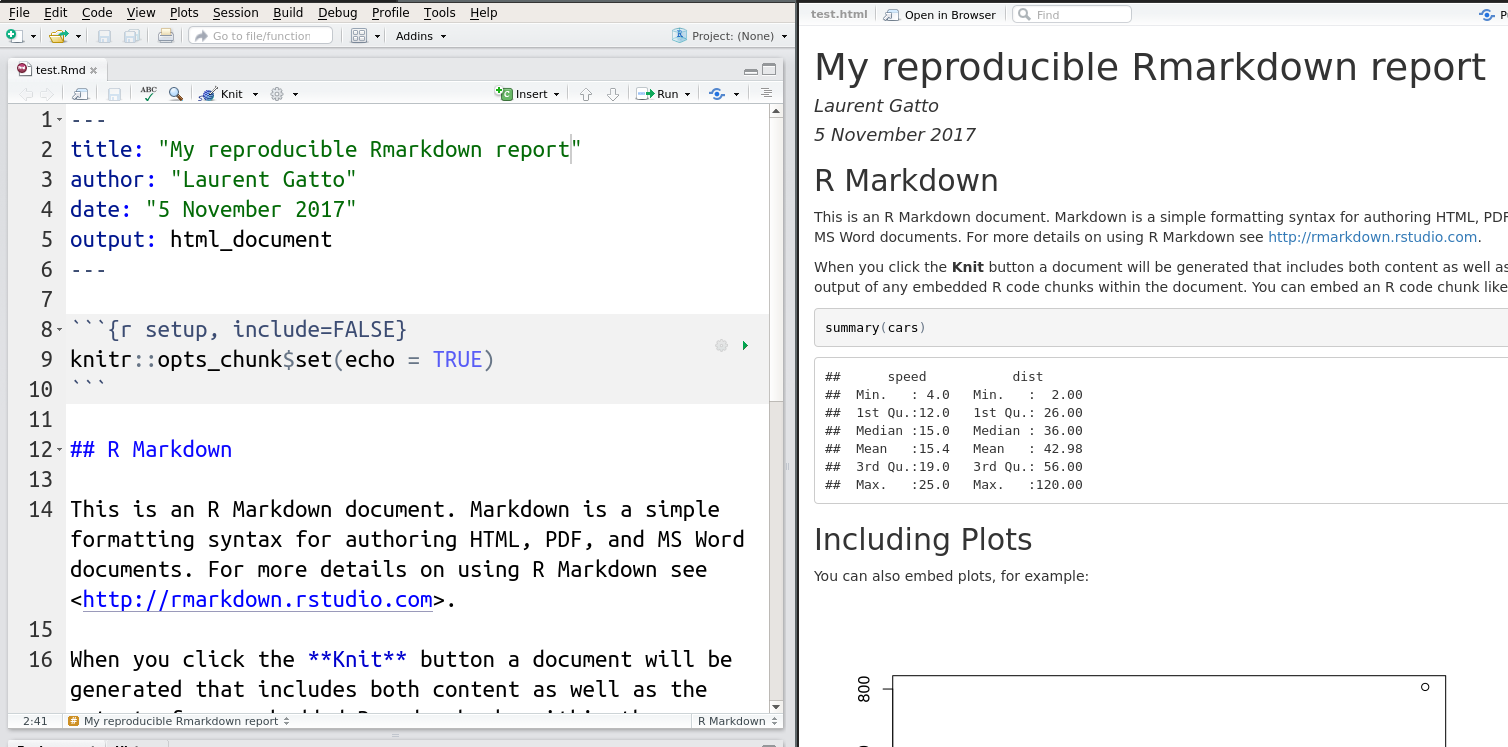
An Rmarkdown document is composed of
An optional YAML header, delimited by
---.Text in simple markdown format.
One or more R code chunks delimited by three backticks. Each code chunk can be uniquely named and parametrised with a set of code chunk options.
These respective parts of an Rmd file are show below and will be
demonstrated during the course.
RStudio also supports Notebook documents16 See also Jupyter notebooks initially developed for Python, but that can run R code as well. that execute individual code chunks independently and display directly in the source document.
Here is an R markdown cheat sheet provided by RStudio and an introduction article.
The following video, R Markdown: The bigger picture by Garrett Grolemund at a 2019 RStudio conference provides a very nice introduction on the many reasons why writing reproducible documents in essential in data science and biomedical research.
8.2 Additional features
Among the most options that can set for code chunks is
cache. Settingcache = TRUEwill avoid that specific code chunk to be cached and not recomputed every time the documented in knitted, unless the code chunk was modified. This is an important feature when long computations are necessary.The
DT::datatablefunction allows to create dynamic tables directly from R, as show below.
- It is always useful to finish a Rmarkdown report with a section
providing all the session information details with the
sessionInfo()function, such at the end of this material. This allows readers to review the version of R itself and all the packages that were used to produce the report.
Using Rmarkdown, it is also possible to produce slides, websites, and complete books, interactive documents and R package vignettes.
► Question
Prepare an Rmarkdown report summarising the portal ecology data. The report should include a Material and methods section where the data is read in (ideally from the online file) and briefly described, a Data preparation section where rows with missing values are filtered out, and a Visualisation section where one or two plots are rendered. Finish your report with a Session information section.
The R Markdown Cheat Sheet and Reference Guide will help you with the markdown synatax, R code chunk options, and RStudio utlisation.
Note: When you prepare an Rmd report, it is advised to start
with a code chunk that load all packages, and update that code chunk
as you proceed with your analysis and use new packages. This avoids
the situation where some commands work in your R console (where you
initially loaded the package) but fail when you compile your
report. Indeed, an Rmd file is compiled in a new, clean R session,
without access to your working session, the packages that were loaded,
and the variables that were created.
8.3 Docker containers
There are other tools for reproducible research, that aim to disseminate more than code and data. Docker containers for example enable to share the complete image of an operating system, including all system dependencies and software/data to repeat a complete analysis. These are useful tools, even though their aren’t necessarily ideal, and beyond the aim of this course. In the annex, (chapter 12), we show how to use a pre-build course-specific RStudio cloud instance based on the Renku infrastructure.
8.4 Additional exercises
► Question
Repeat the Beer consumption analysis using the that was done in chapters 5 and 6.
To test if your report is fully reproducible, uniquely name the Rmd
file as surname_surname_beers_report.Rmd, post it on the course
forum and ask your neighbour to download it, compile it into pdf and
provide feedback on whether the document was reproducible and easy to
follow17 This is an important exercise, as it will mimic the exam
situation, where you will hand in your Rmd reports that will
need to be compiled (to pdf) before marking. In addition, it
demonstrates the challenges of writing and reproducing an
understandable and reproducible document..
► Question
- Create a new R markdown file called
student_results.Rmd, to be compiled in either pdf or html. Remove everything but the lines containing the header. In the example below, the header is composed of the 6 first lines, starting and ending with---.
---
title: "Student results"
author: "Laurent"
date: "March 14, 2020"
output: pdf_document
---- Add a first section called Data input, in which you will load the
rWSBIM1207package, use theinterroA.csv()function to get the name of a csv file containing test results for a set of students, and read these data into R usingread_csv. 18 It is important here not to copy/paste the filename returned byinterroA.csv(). That file is distributed with therWSBIM1207package, and has a computer-specific path. Because we want our reports to be reproducible, we want to use the filename as returned by the function on any computer, not the one of a specific computer. Make sure you either passinterroA.csv()directly toread_csv()or store its output into a variable that is passed toread_csv(). Display the few first observations and write a short sentence explaining the data.
Make sure that you can compile you
Rmdfile into either pdf or html.-
Create a new section called Data visualisation.
Here, the goal is to visualise the score distributions for the four tests using
ggplot2. These distributions will be visualised using boxplots. You will need to visualise these distribution for each test separately, and for male and female students. As discussed during the course, we need data in a long format to be able to use
ggplot2. Start by converting these data into a long format usingpivot_longer(). Display the first rows of these new data and write a short sentence describing them and the transformation you just applied.Use
ggplot2to visualise the score distributions along boxplots for each test and for female and male students.
Page built: 2026-04-02 using R version 4.5.0 (2025-04-11)